
はじめに
前回の記事では「ローカルLLMでOpenClawは厳しい!」と結論づけましたが、諦めるのは早かったことがわかりました。
Ollamaの新モデル Qwen3.6-35b-a3b を適切に設定することで、OpenClawが実用的に使えることを発見しました。特に、エージェントとしての「自走能力」が大幅に向上し、DeepSeek-v3.2と比較しても遜色ないレベルになりました。
[2026-04-28 修正] 公開後に実測値の誤りと設定の記載ミスが見つかったため、本記事を修正しました。
ハードウェア構成と課題
環境スペック
私の環境は以下の通りです。
- CPU: Ryzen 5 5600X
- メモリ: 32GB
- GPU: RTX 3060 12GB
Qwen3.6-35b-a3bは約28.4GBのモデルサイズなので、GPUメモリだけでは完全に載り切りません。当初は挫折ポイントでしたが、Ollamaが自動的に解決してくれます。特別な設定は不要で、OllamaはVRAMに収まる分を自動でGPUに載せ、残りをシステムRAMにオフロードします。
実際の配分(実測値):
- VRAM(GPU): 11.7GB(12GBのうち約95%)
- RAM(CPU): 16.7GB
速度について
画像はRTX3060 12GB(GPUメモリ約95%使用)+ Ryzen 5600Xの環境で、Qwen3.6-35b-a3bをGPU+RAMハイブリッドで動かした時のベンチマーク結果です。
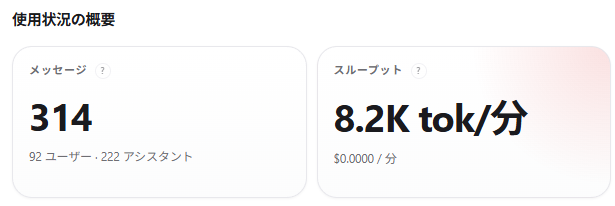
実測の生成速度は 8.2K tok/分(約136 tok/秒) です。RAMへのオフロードが発生しているため、メモリ帯域がボトルネックとなり、純粋なGPU推論と比べて遅くなります。長いレスポンスの生成には数十秒〜数分かかるケースもあります。
即レス前提の用途には向きませんが、エージェントとして複数ステップのタスクを自律的にこなす用途では十分実用的です。
OpenClawの設定変更点
タイムアウト延長
ローカルモデルの応答時間を考慮し、OpenClawのタイムアウトを延長しました:
"timeoutSeconds": 600
デフォルトより大幅に延ばし、現在は600秒(10分)に設定しています。これにより、長い思考プロセスや複雑なコード生成でも確実に完走します。
モデル設定の最適化
~/.openclaw/openclaw.json に以下の設定を追加:
{
"agents": {
"defaults": {
"model": {
"primary": "ollama/qwen36-35b-agent",
"fallbacks": [
"openrouter/deepseek/deepseek-v3.2",
"ollama/gemma4-e2b-agent"
]
}
}
}
}
重要なポイント:primaryモデルをOllamaに設定。これにより、普段使いはローカルモデル、必要に応じてDeepSeek-v3.2にフォールバックという構成です。
コンテキスト設定の秘訣
これが最大のポイントです:
{
"agents": {
"defaults": {
"contextTokens": 131072,
"models": {
"ollama/qwen36-35b-agent": {
"params": {
"num_ctx": 131072
}
}
}
}
}
}
contextTokens: 131072 – 128Kトークンのコンテキスト(OpenClaw側の設定)num_ctx: 131072 – Ollama側への明示的な指定(モデルに渡すパラメータ)
なぜこれが重要なのか?
OpenClawはエージェントとして動作する際、以下のような大量の情報をコンテキストに保持します:
- 会話履歴
- ファイル内容
- ツール仕様
- 実行結果
- 思考プロセス
16Kトークンなど小さなコンテキストでは、すぐに履歴が消えて「自走」できなくなります。エージェントとして使うなら、ある程度のコンテキスト容量は必須です。
なぜ128K(131072)なのか?
KVキャッシュはVRAMの空きがないためRAMにオフロードされます。このKVキャッシュのサイズはコンテキスト長に比例して増加します。
- 131072トークン時のKVキャッシュ: 約12.4GB → RAM 32GBなら余裕あり ✅
- モデルの対応コンテキスト上限(131K)で動作確認済み
当初はRAMが16GBと思い込んでいましたが、実際は32GB搭載していることが判明。128KのKVキャッシュ(約12.4GB)はシステムRAMに余裕をもって収まります。
また、compactionが余裕をもって起動するよう reserveTokensFloor も合わせて設定します:
{
"agents": {
"defaults": {
"contextTokens": 131072,
"compaction": {
"reserveTokensFloor": 20000
}
}
}
}
reserveTokensFloor はコンテキスト残量がこの値を下回ったときにcompaction(要約・圧縮)が走る閾値です。大きくするほど早めに圧縮が起動し、溢れを防ぎます。
Qwen3.6-35b-a3bの実力評価
DeepSeek-v3.2との比較
興味深いことに、特定のタスクではDeepSeek-v3.2より自走能力が高いケースがありました:
| 比較項目 | Qwen3.6-35b-a3b (ローカル) | DeepSeek-v3.2 (API) |
|---|---|---|
| 初期思考時間 | 数十秒〜数分 | 1-3秒 |
| 複数ツール連携 | ◎(文脈維持力が高い) | ○ |
| エージェント継続性 | ◎(コンテキスト保持) | ○ |
| コスト | 電気代のみ | $0.20/100万トークン |
| プライバシー | ◎(完全ローカル) | △(API送信) |
得意なタスク
- 複数ステップのワークフロー
- ファイル読み込み → 分析 → 修正 → コミット のような連続タスク
- 文脈が途切れずに最後まで実行できる
- 長いコンテキストでの作業
- 大量のドキュメントを参照しながらの編集
- 複数ファイルにまたがるリファクタリング
- 「自走」的なエージェント業務
- 指示を受けて必要な情報を自分で探す
- 障害時にもリカバリを試みる
設定のコツと注意点
コンテキスト管理
- 適切なサイズを選ぶ – KVキャッシュのRAM消費を考慮して128K(131072)が利用可能(32GB RAM環境の場合)
- maxTokensも大きく – 8192程度あると長いコード生成が可能
- compactionの閾値も設定する –
reserveTokensFloor: 20000でコンテキスト溢れを防止
実践的な設定例
{
"agents": {
"defaults": {
"model": {
"primary": "ollama/qwen36-35b-agent",
"fallbacks": [
"openrouter/deepseek/deepseek-v3.2",
"ollama/gemma4-e2b-agent"
]
},
"contextTokens": 131072,
"compaction": {
"reserveTokensFloor": 20000
},
"timeoutSeconds": 600,
"models": {
"ollama/qwen36-35b-agent": {
"params": {
"num_ctx": 131072
}
}
}
}
}
}
Ollama側の最適化設定
GPU/RAMへのレイヤー分散はOllamaが自動で行うため、手動指定は不要です。有効にしている設定は以下の通りです:
# /etc/systemd/system/ollama.service.d/override.conf
OLLAMA_FLASH_ATTENTION=1 # メモリ効率化
OLLAMA_KV_CACHE_TYPE=q8_0 # KVキャッシュをQ8量子化で圧縮
OLLAMA_GPU_OVERHEAD=0 # GPU予約領域をゼロに
OLLAMA_MAX_LOADED_MODELS=2 # 同時ロードモデル数
OLLAMA_KEEP_ALIVE=-1 # モデルを常駐させる
コストパフォーマンスの革命
前回の記事では「月$32(約5000円)程度」と報告しましたが、今は電気代のみになりました。
- DeepSeek-v3.2使用時: 約$8/週 → $32/月
- Qwen3.6-35b-a3b使用時: 電気代のみ(月数百円程度)
95%以上のタスクをローカルで処理でき、残り5%の難しいタスクだけDeepSeek-v3.2に任せる。これが理想的な構成です。
今後の展望
この構成で気づいたのは、エージェント向きモデルを選択することが重要だということです。同じ35B級パラメータでも:
- Gemma4-26B: 推論力は高いが、エージェント能力は低い
- Qwen3.6-35b-a3b: バランスが良く、エージェント向き
- Coder系モデル: コード生成特化だが、汎用性に欠ける
OpenClawの強みを活かすには、エージェント能力に特化したモデルを選択するのが鍵です。
まとめ
「ローカルLLMでOpenClawは厳しい」という先入観を覆すことができました。適切なモデルと設定さえ見つかれば、ローカル環境でも十分実用的です。
実現できたこと:
✅ RTX3060 12GBでの実用化(GPU+RAMハイブリッド、設定不要)
✅ 月額コストを$32→ほぼゼロに削減
✅ DeepSeek-v3.2と同等のエージェント能力
✅ プライバシーを維持したAIアシスタント運用
秘訣はたった一つ:
RAMの空き容量を考慮した上で、収まる範囲でコンテキストを大きく取ること
KVキャッシュはVRAMが足りない分だけRAMに自動でオフロードされます。「RAMが許す限り」コンテキストを大きくすれば、ローカルLLMでもOpenClawは十分戦えます。32GBメモリ環境では128K(131072トークン)まで利用可能です。
次は、複数ローカルモデルの動的切り替えや、タスクごとの自動モデル選択に挑戦したいと思います。
この記事は、OpenClaw + Ollama Qwen3.6-35b-a3b によって作成され、人間が微調整しました。
2026-04-28: モデルサイズ・GPU設定・速度計測・コンテキスト設定の誤りを修正
2026-05-04: RAM 32GB確認に伴いコンテキスト128K化・モデル名・タイムアウト設定の誤りを修正
「ローカルLLMでOpenClawが結構使える!Ollama Qwen3.6-35b-a3bの実力」への1件のフィードバック