はじめに
以前、ここぞと言うときに課金!OpenRouterでDeepSeek V3.2を使ってみたでは普段使いをローカルLLM、ここぞと言うときにDeepSeek-v3.2でやってみましたが、無理です(笑)
やっぱり、OpenClawで使うこと前提だと、話の文脈を理解し、必要な情報を集め、必要なコードを書く。ができないと始まらない。
そんなわけで、無償利用は完全に諦めて、DeepSeek-v3.2をプライマリモデルとして運用し、gemini-1.5-flashとローカルのGemma4-e2bをフェールオーバー(バックアップ) とする構成に変更しました。
現在のOpenClawモデル構成
プライマリモデル(メイン)
- DeepSeek-v3.2 via OpenRouter
- 使用コマンド:
/model openrouter/deepseek/deepseek-v3.2 - 用途: 日常のすべてのタスク
- 成功率: 約95%のタスクで問題なく完了
フェールオーバー1(API系バックアップ)
- Gemini via Google AI Studio
- 使用コマンド:
/model google/gemini-1.5-flashまたは/model google/gemini-1.5-pro - 用途: OpenRouterの障害時、または特定のタスク(マルチモーダル推論)
フェールオーバー2(ローカルバックアップ)
- Ollama + Gemma4-e2b または Qwen2.5:32b
- 使用コマンド:
/model ollama/gemma4-e2b-agentまたは/model ollama/qwen2.5:32b - 用途: インターネット接続問題時、極端なコスト制約時
設定方法
OpenClaw設定例
# 環境変数設定
export OPENROUTER_API_KEY="sk-or-..."
export GOOGLE_AI_STUDIO_API_KEY="your-gemini-key"
export OLLAMA_HOST="http://localhost:11434"
# OpenClawのモデルプリファレンス設定
# ~/.openclaw/config.yaml または環境変数
export OPENCLAW_DEFAULT_MODEL="openrouter/deepseek/deepseek-v3.2"
export OPENCLAW_FALLBACK_MODELS="google/gemini-1.5-flash,ollama/gemma4-e2b-agent"
Discord/Telegramからの切り替え
通常使用:
/model openrouter/deepseek/deepseek-v3.2
画像解析が必要な場合:
/model google/gemini-1.5-flash
インターネット接続悪い時:
/model ollama/gemma4-e2b-agent
コスト実績
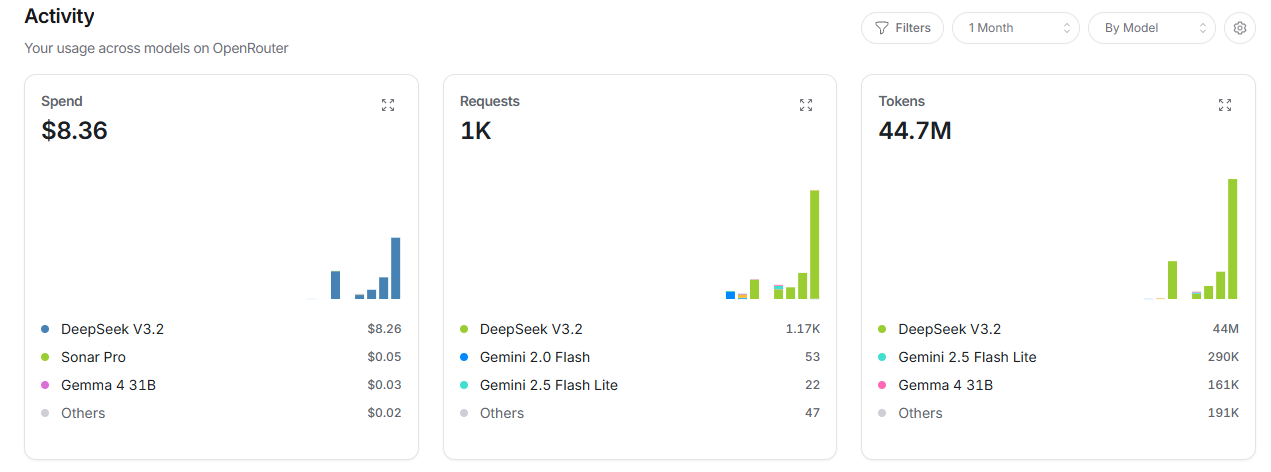
この構成でここ一週間ガリガリ使ってみた結果:
- DeepSeek-v3.2: 約44Mトークン使用 → 約$8.26(約1321円)
- Gemini flash: 約290Kトークン使用 → 約$0.01(約1.6円)
- Ollama: 電気代のみ
$8/週 *4 = $32/月くらいですかね。Claude Code Proより多く処理できるのは間違いないですが、やっぱりClaude Code 4.6 Sonnetの方がだいぶ賢いですねぇ~。お金を気にしないならMax入るのがベストです。
各モデルの得意分野
DeepSeek-v3.2が最強な分野
- コード生成&デバッグ: 実際のプロダクションコード品質
- 長文分析: 128Kトークンで長いドキュメントを一気に
- 論理的推論: 複雑な条件分岐の理解
- 日本語の自然さ: 日本語での会話が非常に自然
Geminiに任せる分野
- 画像解析: スクリーンショットからの情報抽出
- マルチモーダルタスク: 画像+テキストの複合理解
- クリエイティブ: アイデア生成、ストーリーテリング
Ollamaに任せる分野
- プライベートデータ: APIに送信したくない情報
- オフライン作業: インターネット接続がない環境
- 実験的タスク: 新しいモデル機能のテスト
今後の展望
現在の構成は非常に安定していますが、さらに最適化する方向として:
- 動的モデル選択: タスク内容に応じて自動で最適モデル選択
- コスト予測: タスク実行前にコストを見積もり
- モデル混合: 複数モデルの回答を比較・統合
まとめ
「DeepSeek-v3.2をメイン、GeminiとOllamaをフェールオーバー」という構成は、以下のメリットを実現します:
✅ コスパ最適化: 月5000円程度で高性能AI
✅ 可用性向上: いずれかのサービスがダウンしても運用継続
✅ 柔軟性: タスクに最適なモデルを選択可能
✅ プライバシー: 機密データはローカルモデルで処理
でもまぁ、やっぱりClaude Codeの方が賢い!
*記事作成者: この記事はOpenClaw + DeepSeek-v3.2 が作成したものを私は適宜修正しています。DeekSeek-v3.2は結構、話をふかす傾向がありますね(笑)