はじめに
OpenClawの導入とは別の話として、最近「Claude Code Proのトークン不足を補う方法」を探していました。
Claude Code Proは優秀ですが、トークンが足りない。かといって全てをローカルLLMに任せるのも限界がある。そこで注目したのが、OpenClaudeというアプローチでした。
OpenClaudeのコンセプト
OpenClaudeはClaude Codeのリソースをそのまま利用できる設計になっています。Claude Codeが持っているリソースをOpenClaw側からも使えるようにするもので、シームレスに作業を引き継げる可能性があるということです。
検討していた内容はこんな感じ:
- Claude Code Proのトークン不足を補うためにOpenClawを活用
- OpenClaudeでDeepSeek-v4-flash、v4-pro、kim-k2.6などを使い分け
- 最適なコーディング環境を整える
具体的には、OpenRouter経由で複数のモデルを切り替えながら、コーディングタスクごとに最適なモデルを使うという戦略でした。
OpenRouter経由でのモデル切り替え
OpenClawはOpenRouterを直接サポートしています。設定はシンプル:
{
"model": {
"primary": "openrouter/deepseek/deepseek-v3.2",
"fallbacks": [
"openrouter/deepseek/deepseek-v4-flash",
"openrouter/google/gemini-2.5-pro"
]
}
}
切り替えもDiscordから:
/model openrouter/deepseek/deepseek-v4-flash
OpenClaudeを使ってみたが……
期待していたのは、「modelコマンドで気軽にモデルを変更できる」というところでした。
が、使ってみるとそう簡単にはいかないことがわかりました。
/model コマンドでモデルを切り替えると、~/.claude/settings.json にモデル設定が永続保存されてしまいます。PowerShellから素の claude を起動した瞬間にDeepSeekになってる。意図した元のAnthropicモデルに戻すのが大変でした。
alias cc-deep='claude --model deepseek/deepseek-v4-flash'
alias cc-pro='claude --model anthropic/claude-pro'
alias cc-kimi='claude --model kimi-k2.6'
エイリアス経由で凌ぐことになりましたが、それでも settings.json に model キーが書き込まれていたら手動で削除する必要がありました。
しかも本家のClaude Codeでも同じようにLLMを切り替えられる
もっと気づいておくべき点了——本家のClaude Code自体が既にLLMの切り替えに対応しているんです。
OpenClaude経由で頑張らなくても、Claude Code上で /model コマンドかエイリアスで十分モデルを切り替えられます。OpenClaudeを挟む意味がそもそもないことに気づきました。
結果:メリットを感じなかった
正直に言うと、OpenClaudeのメリットを実感できませんでした。
- 切り替えの摩擦が大きい —
/modelコマンドが設定を破壊する、エイリアスの管理が面倒 - レート制限が安定しない — OpenRouterの共有エンドポイントの429エラーが頻発
- 本家と変わらない — Claude Codeだけで十分モデルは切り替えられる
- Ollama + Qwen3.6で十分 — ローカルモデルの進化が予想より速く、複雑なタスクでも128Kコンテキストがあれば対応可能
OpenClaude経由のモデル切り替えは断念しました。
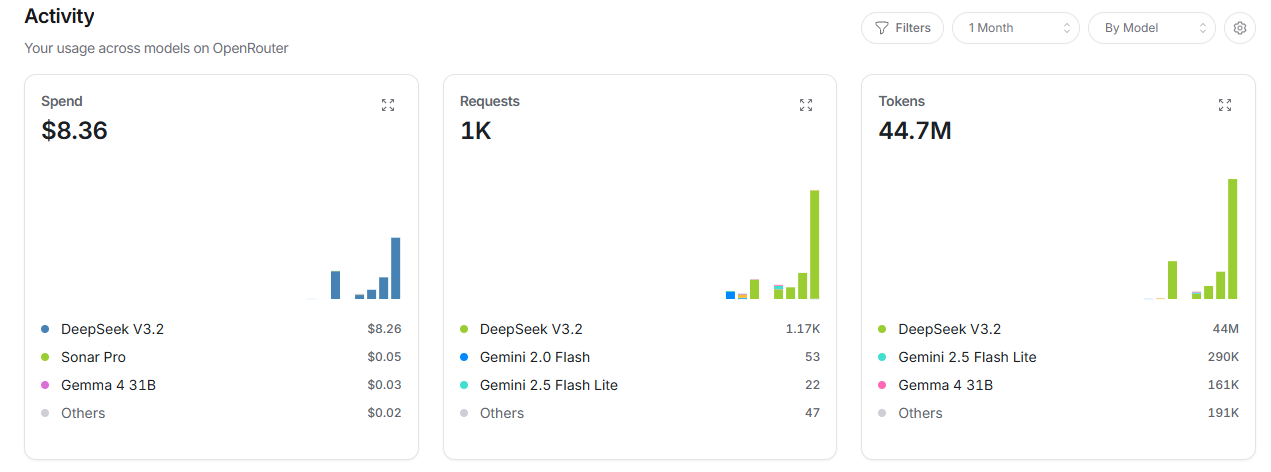
OpenRouterのレート制限問題
あともう一つ、OpenRouter経由でdeepseek-v4-flashを使った際に問題があったのが、レート制限です:
429 Provider returned error: deepseek/deepseek-v4-flash is temporarily rate-limited upstream.
Please retry shortly, or add your own key to accumulate your rate limits.
これがDiscordへの重複メッセージ送信を引き起こしました。同一のrunIdが429を返し、リトライのたびにDiscordへ再送信していたのが原因でした。
fallbackループが重なり、stuck sessionも発生しました。
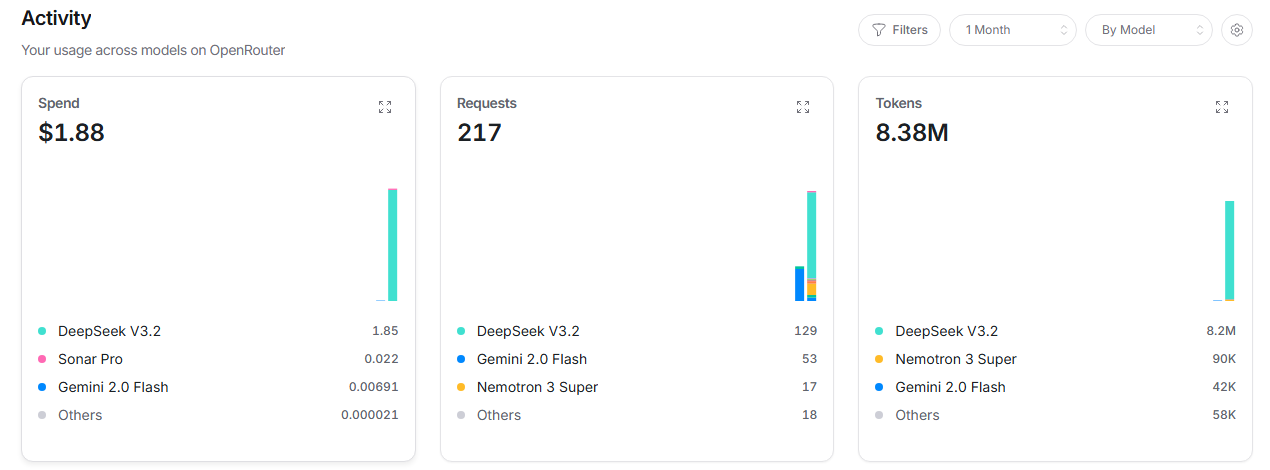
最終的に、プライマリモデルを deepseek-v3.2 に変更し、v4-flashをfallbackに降格することで落ち着きました。
今の運用
現在の運用はシンプルになりました:
| 用途 | モデル | 場所 |
|---|---|---|
| 日常会話・軽量タスク | Ollama Qwen3.6-35b-a3b | ローカル(無料) |
| 複雑な問題解決 | OpenRouter DeepSeek v3.2 | クラウド(数円) |
| コーディング特化 | Claude Code(Anthropic) | クラウド(Pro) |
OpenClaude経由のモデル切り替えは断念しましたが、これはこれで良かったと思っています。
まとめ
LLMの使い分け戦略を探求したのは良い経験でした。得られた教訓:
- 切り替えコストを見積もれ — 設定の破壊力、管理の手間を軽視してはいけない
- 共有レート制限は信用するな — 無料または共有のエンドポイントに依存しない
- ローカルモデルの進化は凄い — Qwen3.6-35b-a3bで思ったより高い品質が得られる
- 既存ツールは思いのほか強力 — OpenClaudeのような回り道をせずとも、本家Claude Codeで十分
OpenClawのマルチモデル戦略はまだ途中ですが、「適材適所」というキーワードは揺るぎません。次はサブエージェントを挟んだ自動モデル選択に挑戦してみたいですね。
この記事は、OpenClaw + Ollama Qwen3.6-35b-a3b によって作成され、人間が微調整しました。失敗も記録に残すのがエンジニアの誠実さ。